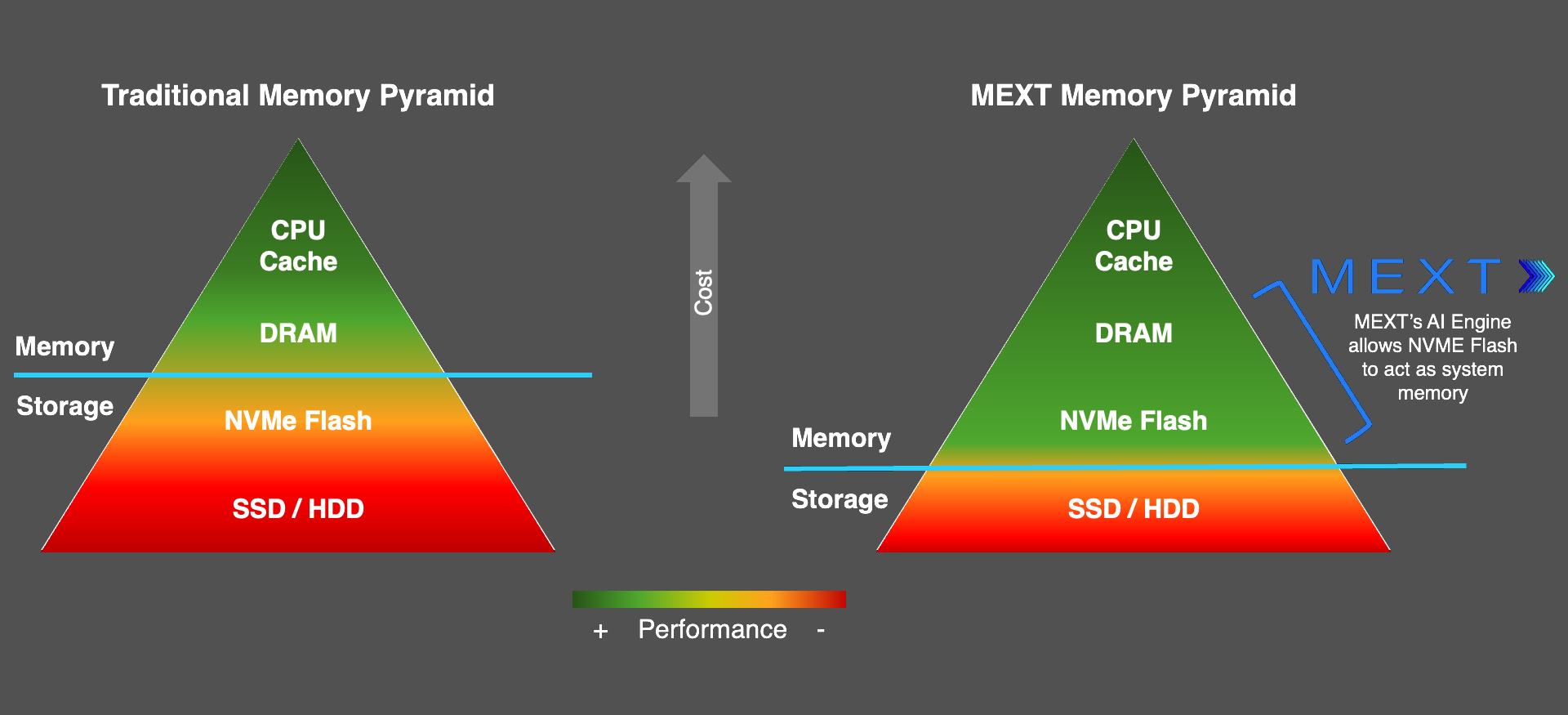
Huawei and SiliconFlow describe speedy LLM for CloudMatrix 384
"Our extensive evaluation with the DeepSeek-R1 model shows that CloudMatrix-Infer achieves state-of-the-art efficiency without sacrificing accuracy. CloudMatrix-Infer delivers a prefill throughput of 6,688 tokens/s per NPU, and a decode throughput of 1,943 tokens/s per NPU (at ¡50 ms TPOT). These results correspond to compute efficiencies of 4.45 tokens/s/TFLOPS for prefill and 1.29 tokens/s/TFLOPS for decode, both exceeding published results for SGLang on NVIDIA H100 and DeepSeek on NVIDIA H800. CloudMatrix-Infer also effectively manages the throughput-latency trade-off, sustaining a 538 tokens/s decode throughput even under the stricter sub-15 ms TPOT constraint. Furthermore, the INT8 quantization on Ascend 910C maintains model accuracy comparable to the official DeepSeek-R1 API across 16 distinct benchmarks."